
It was only a matter of time before I came across a client using a headless CMS.
There’s a lot to be said about the benefits and drawbacks of headless CMSes beyond technical SEO.
But I won’t be saying it here. Except as it pertains to the specifics of this case study.
If you want to learn more about headless CMSes, this article is a good place to start.
Background
This particular client had built their website using a headless CMS without much thought towards marketing or SEO.
And that’s a problem. With a headless CMS, lack of forethought causes a lot of preventable problems.
With a traditional CMS (which is what most people use) like WordPress, you can cover a lot of the basic SEO stuff with Yoast. Just install the plugin and with some simple configuration you can more or less control:
- Canonical links
- Redirects
- Meta descriptions
- Title tags
- Structured data
- No indexing
- URL formatting
With a headless CMS, you have to specifically ask your developers to add functionality to create and edit URL formats, add structured data, implement redirects, etc.
Unfortunately for this client, neither their content people nor their developers knew enough about technical SEO to anticipate this when they built their site.
And that’s where I came in.
Approach
The client initially came to me with some ideas about what they wanted, but their main goal was to get in front of their ideal customer. So they were open to suggestions.
Instead of jumping right into content as they’d initially intended, I recommended a technical SEO audit.
With just a preliminary look, I could tell there were all kinds of technical issues. And like I tell all my clients, if you have serious technical issues, all your investments in content are going to be dragged down by your technical debt.
So we decided to put off content for the time being and proceed with a technical audit.
Technical Issues Identified and Dealt With
I won’t go into full detail on all fixes here, but I will review the most impactful. If you’d like to skip to the results, scroll past this section.
Irrelevant pages being crawled
My client’s headless CMS seemed to be dynamically generating thousands of URLs with random strings of numbers. This resulted in over 4000 irrelevant pages on the site being crawled by Google.
You could argue this was a small enough number of URLs to not be a crawl budget issue. But I was worried that these pages were going to continue to be generated, which would become a crawl budget issue.
Fortunately, though I wasn’t told why these pages existed, the dev team assured me they wouldn’t continue to be generated. And follow-up crawls confirmed they were speaking the truth.
Still, there was the issue of the 4231 crawled but not indexed pages.
To reduce that number, I helped the dev team by suggesting a quick adjustment to the robots.txt file.
Problem: 4231 duplicate pages being crawled but not indexed.
Fix: Adjust robots.txt and eliminated source of dynamically generated duplicate pages.
Results: 4231 pages crawled but not indexed reduced to 856* and no more dynamically generated duplicates.
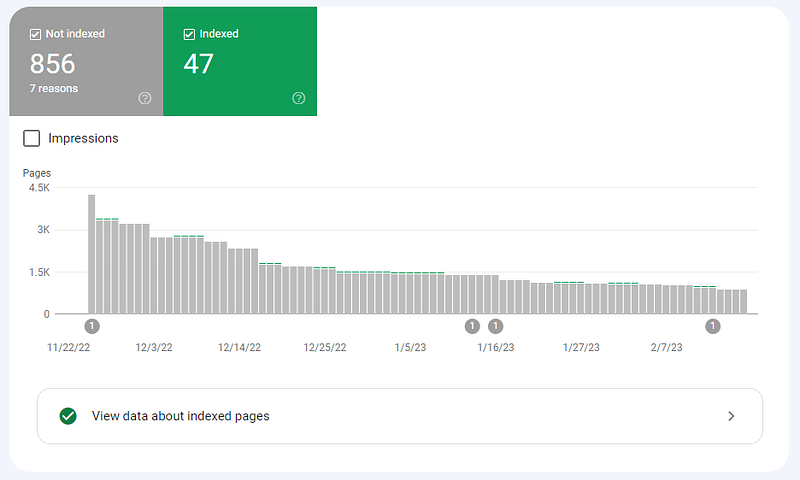
*By the time I published this post, it had fallen further, from 856 to 295.
Duplicate content issues
Three problems were causing most of the site’s pages to have duplicate content issues.
1. No meta tag control
First, the publishing workflow had been set up so page titles and meta descriptions were duplicated when you created a new page. And content editors either couldn’t or were choosing not to change the page titles or descriptions.
We fixed that by adding a plugin called: gatsby-plugin-next-seo. This gave content editors an easy way to edit titles and descriptions.
2. Incorrectly implemented redirects
The second problem was two-pronged: a litany of soft 404s were being caused by meta refresh redirects back to the homepage which had been applied on about 90 pages.
The first prong of this problem was that redirecting pages to the homepage is not best practice, and Google has been clear on that for years.
The second prong was that meta refresh redirects aren’t ideal for user experience or SEO. So I wanted to make sure if any URLs were permanently redirected in the future, the team would use 301s instead of meta refresh redirects.
3. Missing redirects
The third problem was that no consistent URL format had been established for the site.
WWW and non-WWW versions of the same URL were both resolving when they should’ve been redirecting to one or the other version.
For example, you could reach both of these pages:
- www.sampledomain.com/about-us/
- sampledomain.com/about-us/
Non-trailing slash (e.g. www.sampledomain.com/about-us) and trailing slash URLs (e.g. www.sampledomain.com/about-us/) were doing the same.
As a result, there could be up to 4 different versions of the same page.
And that’s terrible for SEO because any authority signals (like links) the site got would be diluted among these 4 pages. Also, Google will be confused which page to index.
Case in point: 4 different versions of the home page were all indexed on separate URLs.
Problem: Multiple versions of key pages (home, about, etc.) were being crawled and indexed, soft 404’d, and had duplicate titles and meta descriptions.
Fix: Change home page redirects to the correct, corresponding URL; replace meta refresh redirects with 301s, and redirect non-trailing-slash, non-WWW URL formats to trailing slash, www-URL formats.
Results: 100+ duplicate content issues eliminated, consolidated link signals, and improved user experience.
Results
I prioritized my recommendations for my client and collaborated with their dev team to implement.
My extensive documentation meant we only had to go back and forth in a few emails and all changes were made between December 12th and 26th.
(By the way: if you’d like my technical SEO audit template, leave a comment on this post.)
Here’s how their weekly click and impression totals changed.
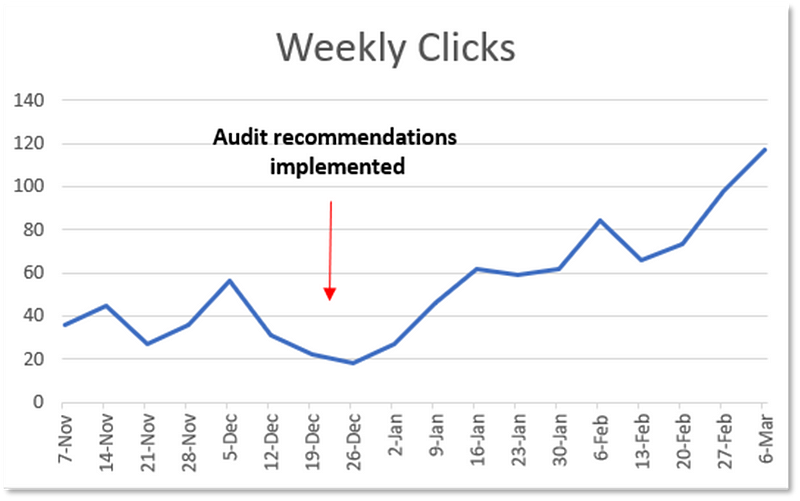
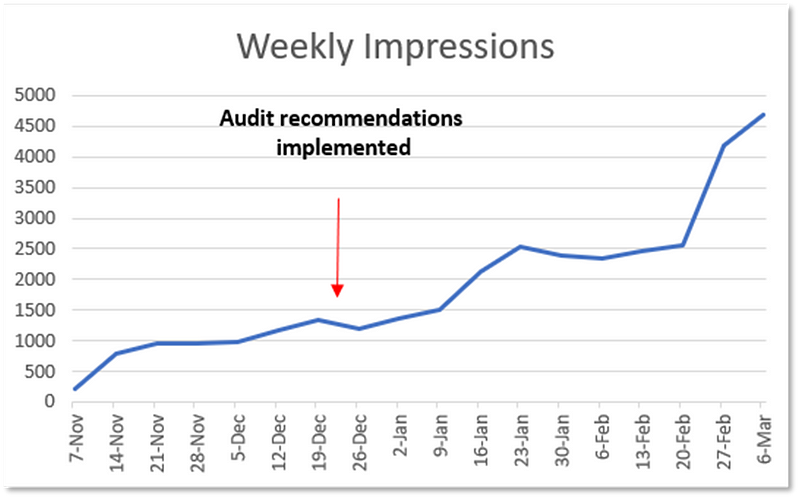
While we all love more impressions and clicks, in this case, I was most excited about the massive increase in total keywords the domain ranked for.
Total keywords shot up from 134 before the audit to 697 a couple months after the audit for a 4.2X increase.
And for those interested in the nerdy technical SEO wins, here are a few metrics from SEMRush’s crawl comparison:

This growth will level out.
Measuring performance before and after a technical SEO audit is like measuring your physical ability to jump after fully rehabilitating your injured knee.
If you plotted the growth curve of your jumping performance before and after your injured knee, you’d be astounded. But you wouldn’t expect your growth to continue on that trajectory.
Even so, this is a powerful demonstration of how much technical issues can be holding your site back.